DeepNLME
Neural Networks, SciML, and Universal Differential Equations
2025-10-12
Traditional NLME
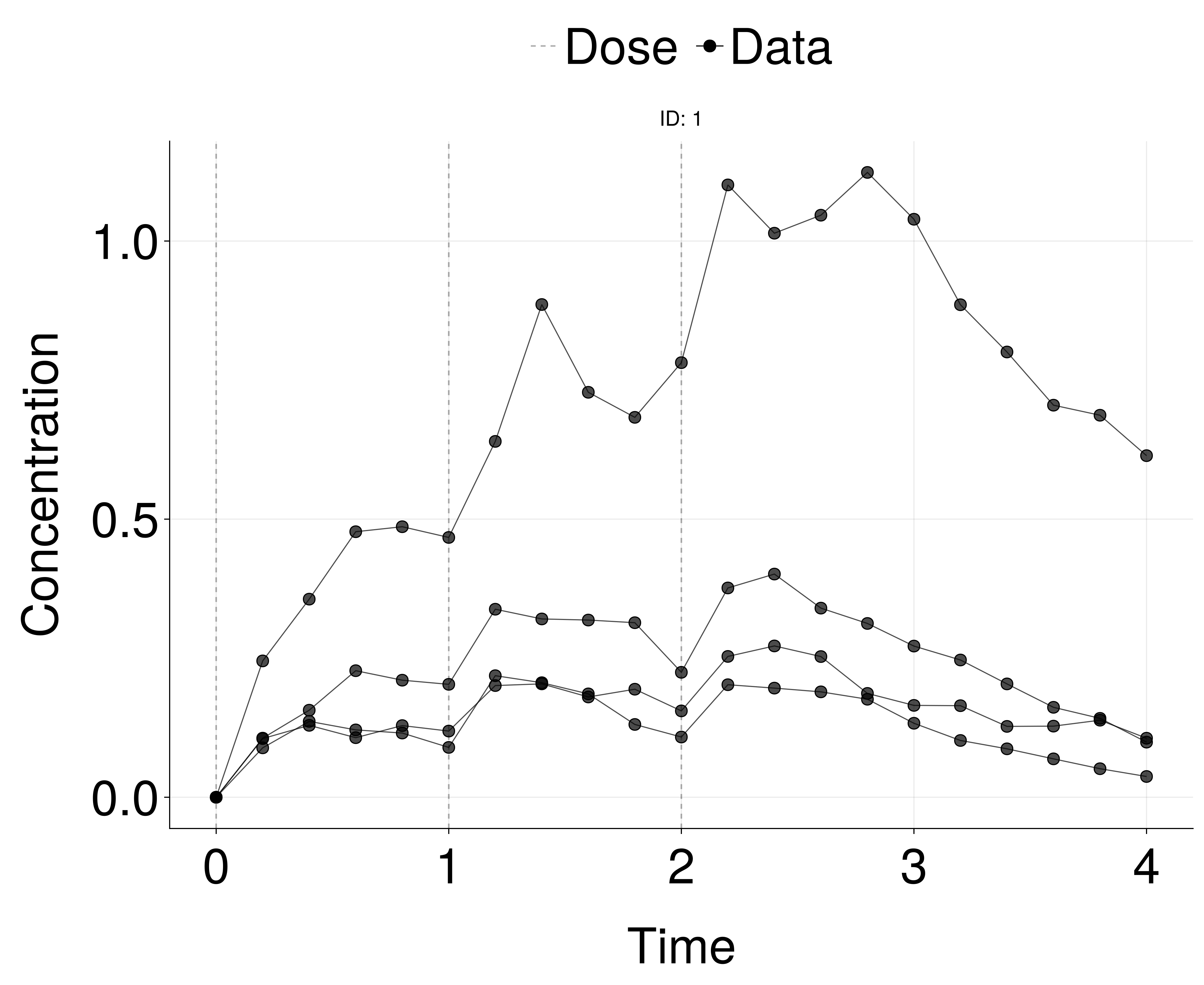
Nonlinear Mixed Effects
Typical values \[ tvKa, \; tvCL, \; tvVc, \; Ω, \; σ \]
Covariates \[ Age, \; Weight \]
Random effects \[ η \sim MvNormal(Ω) \]
Individual parameters \[\begin{align*} Ka_i &= tvKa \cdot e^{η_{i,1}} \\ CL_i &= tvCL \cdot e^{η_{i,2}} \\ Vc_i &= tvVc \cdot e^{η_{i,3}} \end{align*}\]
Dynamics \[ \begin{align*} \frac{dDepot(t)}{dt} =& - Ka \cdot Depot(t) \\ \frac{dCentral(t)}{dt} =& Ka \cdot Depot(t) - \frac{CL}{Vc} \cdot Central(t) \end{align*} \]
Error model \[ dv(t) \sim Normal\left(\frac{Central(t)}{Vc}, \frac{Central(t)}{Vc} \cdot σ\right) \]
What if components are unknown?
Nonlinear Mixed Effects
Typical values \[ tvKa, \; tvCL, \; tvVc, \; Ω, \; σ \]
Covariates \[ Age, \; Weight, \; \color{red}{???} \]
Random effects \[ η \sim MvNormal(Ω) \]
Individual parameters \[\begin{align*} Ka_i &= tvKa \cdot e^{η_{i,1}} \\ CL_i &= tvCL \cdot e^{η_{i,2}} \cdot \color{red}{???} \\ Vc_i &= tvVc \cdot e^{η_{i,3}} \end{align*}\]
Dynamics \[ \begin{align*} \frac{dDepot(t)}{dt} =& - Ka \cdot Depot(t) \\ \frac{dCentral(t)}{dt} =& Ka \cdot Depot(t) - \color{red}{???} \end{align*} \]
Error model \[ dv(t) \sim Normal\left(\frac{Central(t)}{Vc}, \frac{Central(t)}{Vc} \cdot σ\right) \]
Neural networks
Information processing mechanism
- Loosely based on neurons
![]()
- Mathematically just a function!
- Usable anywhere you’d use a function!
Neural networks in NLME dynamics
Focus: Neural Networks in Dynamics
Typical values \[ tvKa, \; tvCL, \; tvVc, \; Ω, \; σ \]
Covariates \[ Age, \; Weight \]
Random effects \[ η \sim MvNormal(Ω) \]
Individual parameters \[\begin{align*} Ka_i &= tvKa \cdot e^{η_{i,1}} \\ CL_i &= tvCL \cdot e^{η_{i,2}} \\ Vc_i &= tvVc \cdot e^{η_{i,3}} \end{align*}\]
Dynamics ← This lecture focuses here \[ \begin{align*} \frac{dDepot(t)}{dt} =& - Ka \cdot Depot(t) \\ \frac{dCentral(t)}{dt} =& Ka \cdot Depot(t) - \color{red}{NN(...)} \end{align*} \]
Error model \[ DV(t) \sim Normal\left(\frac{Central(t)}{Vc}, \frac{Central(t)}{Vc} \cdot σ\right) \]
