Random effects
And how they interact with machine learning
2025-10-12
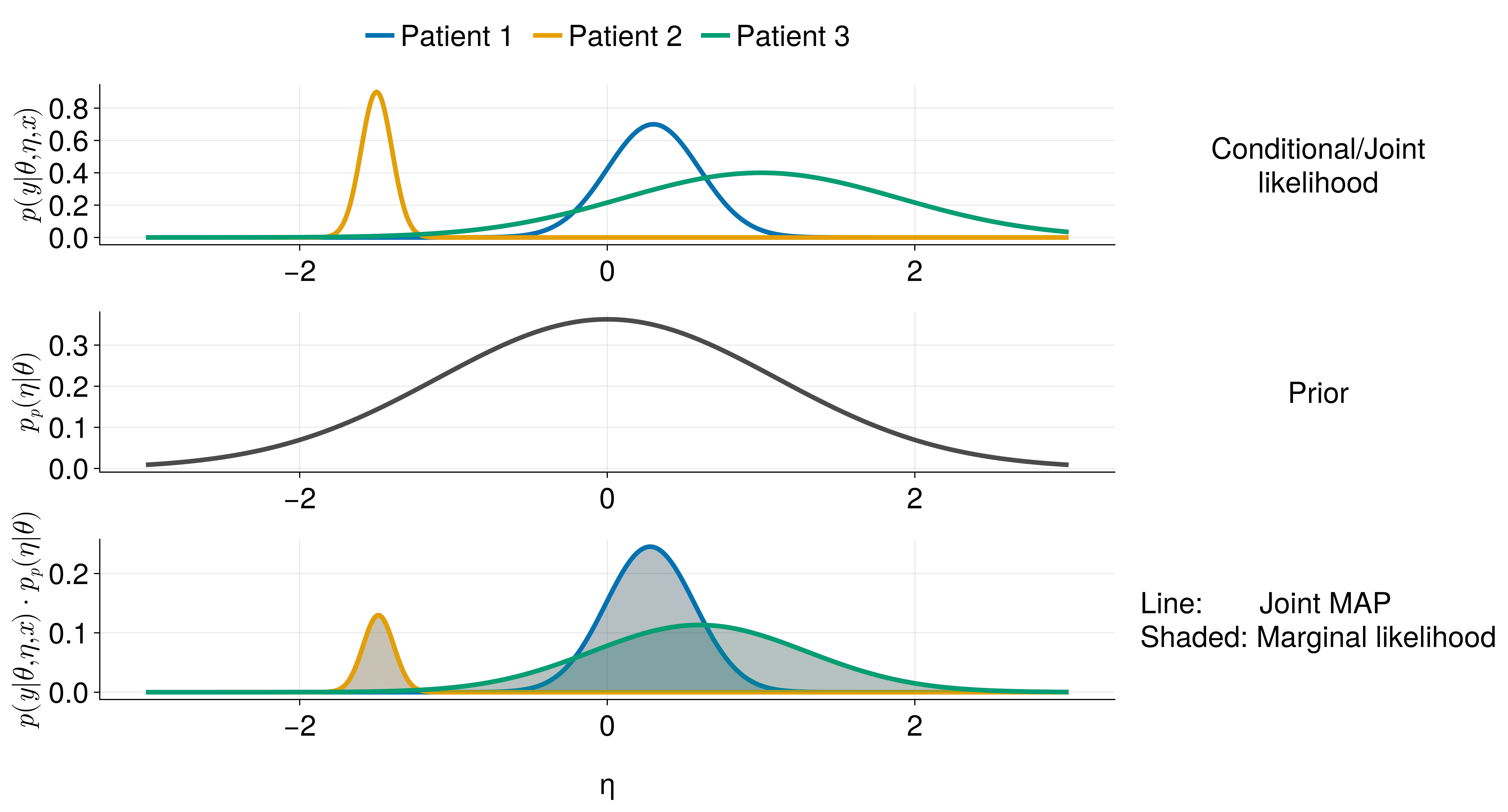
Fitting with random effects
“Smoothness”?
Classical NLME \[ EFF = \left(1 + Smax \cdot \frac{C}{tvSC50 \cdot exp\left(\mathbf{\eta}\right) + C}\right) \]
- This function is somewhat smooth in \(η\) by structural definition.
- Very little flexibility to affect the smoothness by tuning fixed effects.
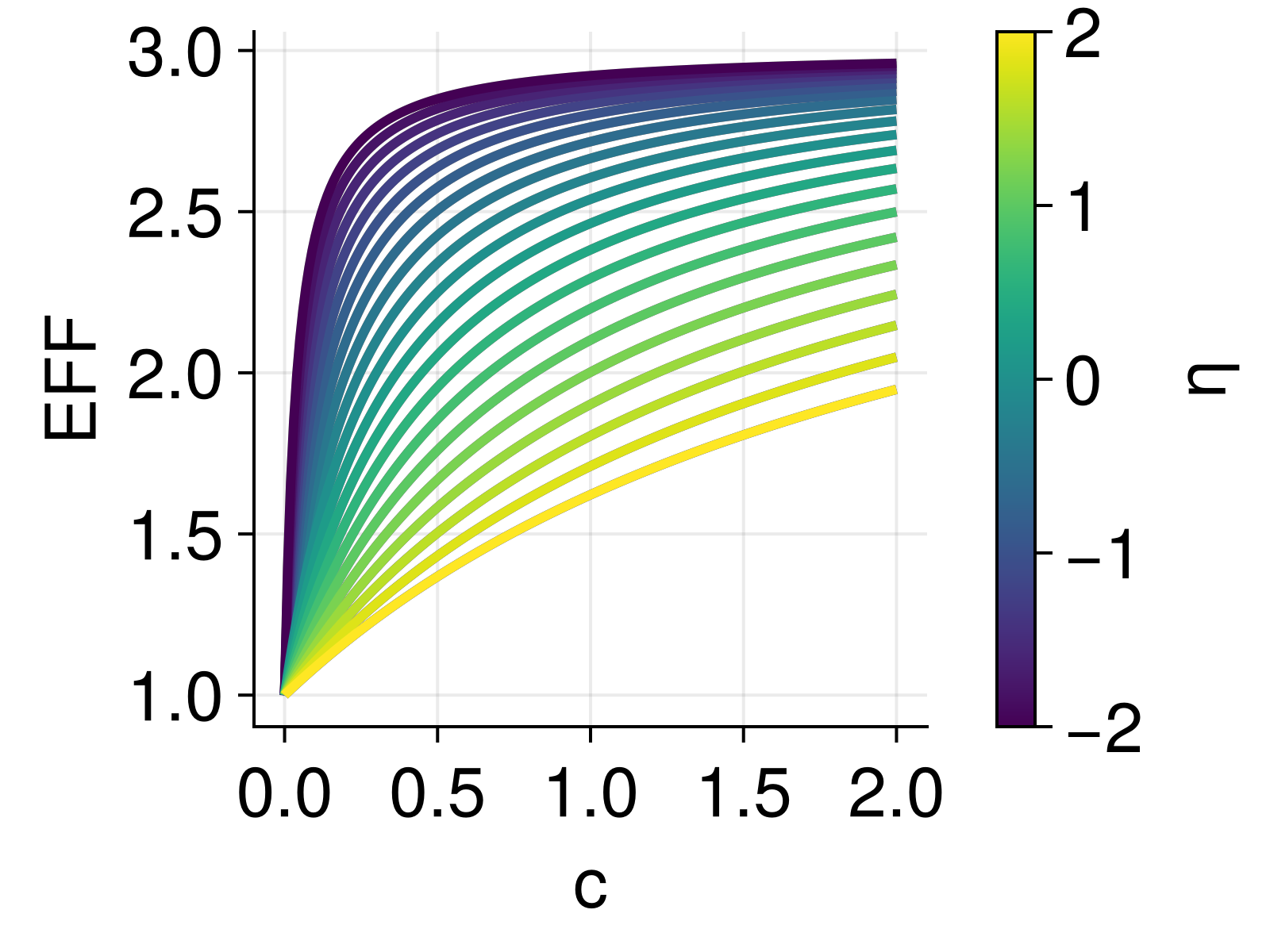
DeepNLME
\[ EFF = \left(1 + NN(C, η)\right) \]
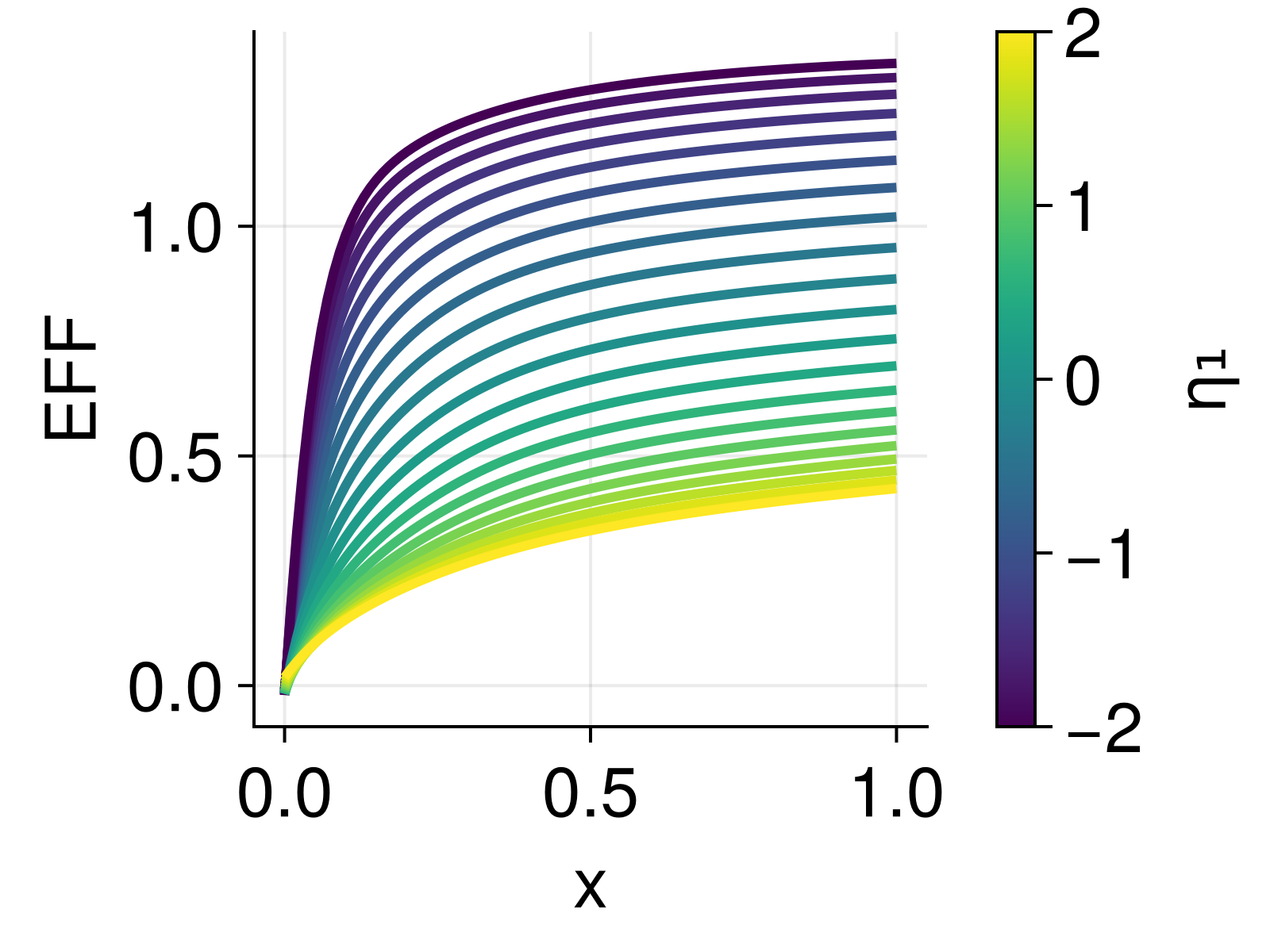
- This function can be very non-smooth in \(η\).
- Lots of flexibility to affect the smoothness by tuning fixed effects.
- Incentivizing smoothness by marginalization in the fit really helps here!
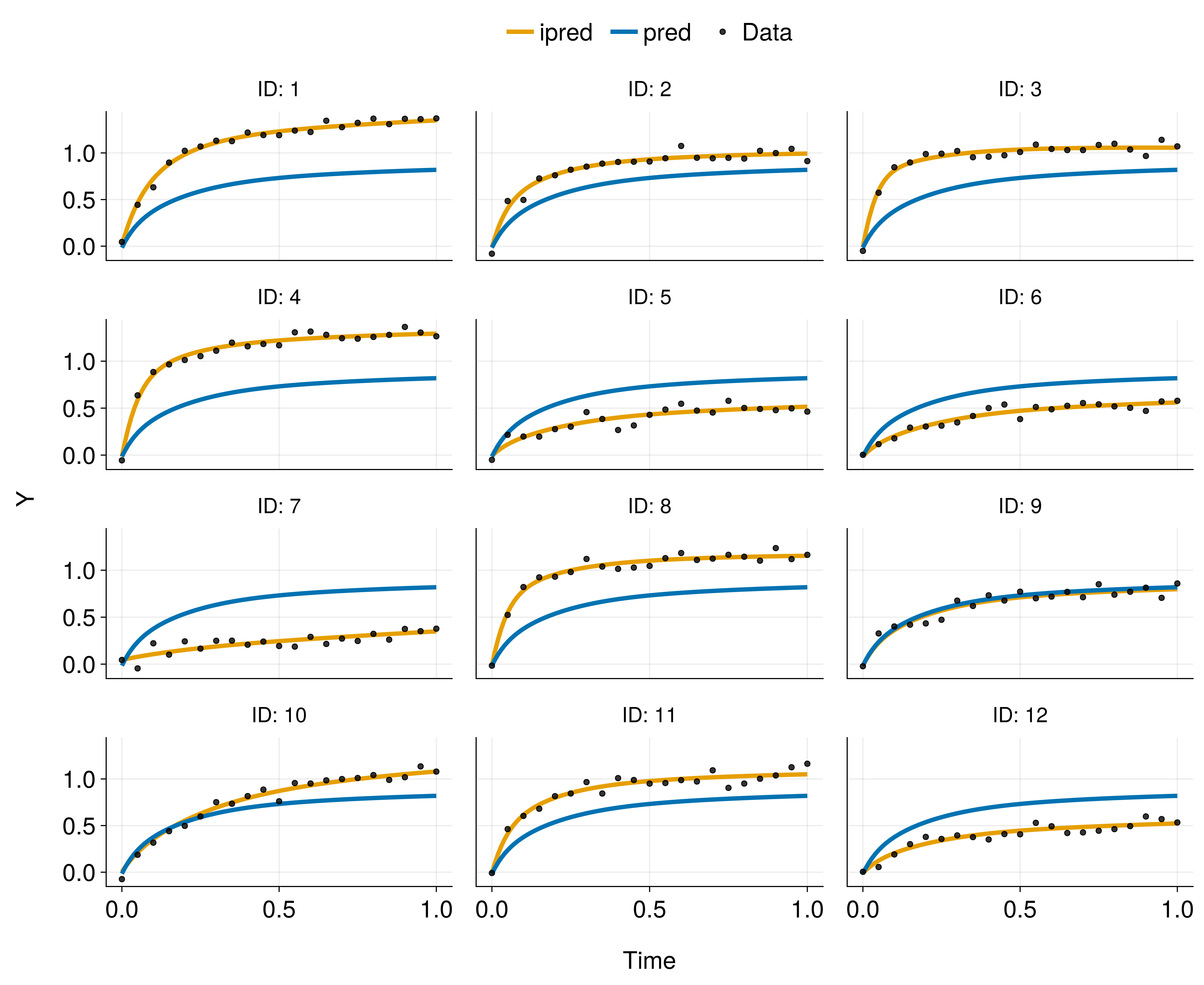
Smoothness in DeepNLME
Data-generating function: \[ Y = \frac{E_{max} \cdot x}{EC_{50} + x} + \epsilon, \quad \epsilon \sim \mathcal{N}(0, \sigma^2) \]
where \[ \begin{align} E_{max} &\sim \mathcal{U}(0.5, 1.5) \\ EC_{50} &\sim \mathrm{LogNormal}(-2, 1.0) \end{align} \]
DeepNLME model: \[ \begin{align} Y &= {\color{orange}NN(x, η₁, η₂)} + \epsilon, \quad \epsilon \sim \mathcal{N}(0, \sigma^2)\\ η &\sim \mathcal{N}(0, I) \end{align} \]